 Sentienta Blog
Sentienta Blog Sentienta has already redefined how teams of agents research, analyze, and reason through complex problems.
Sentienta has already redefined how teams of agents research, analyze, and reason through complex problems.
With our latest release, those teams can now carry that work all the way through to completion.
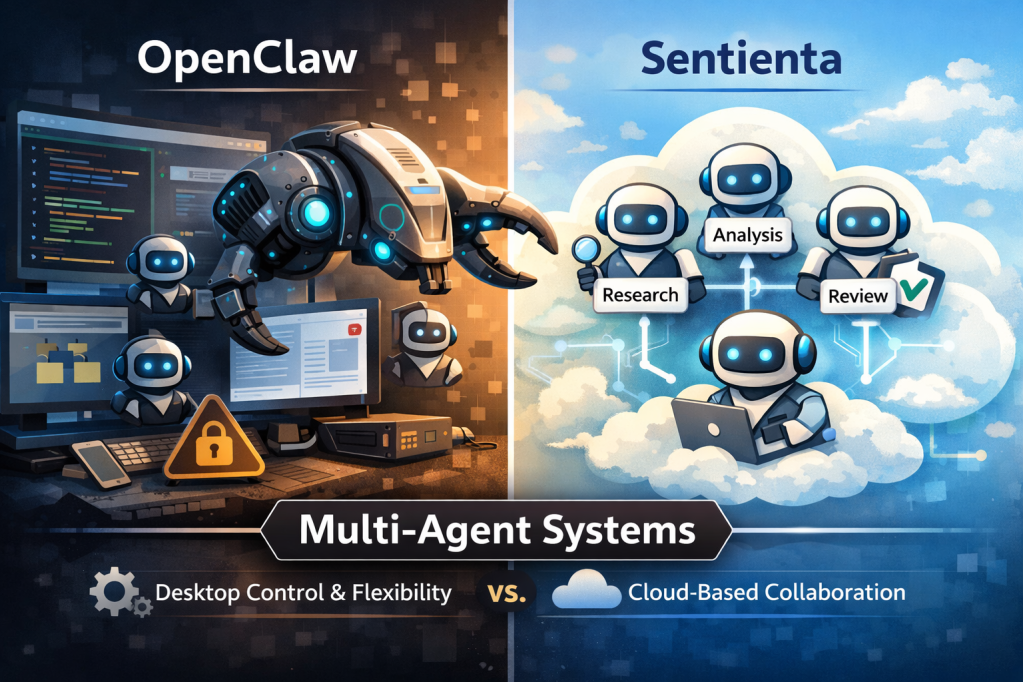
By integrating OpenClaw, Sentienta Teams can recruit specialized third-party agents to execute tasks directly in owner-controlled desktop environments—turning high-level strategy into finished, usable outputs without leaving the workflow.
The Power of an Open Ecosystem
This release isn’t just about a new feature—it changes how Sentienta grows.
Sentienta’s strength has always been orchestration. With OpenClaw, that orchestration now extends to a rapidly evolving ecosystem of external agents.
Whether it’s a dedicated web researcher or a document automation specialist, if it speaks OpenClaw, it can join your Sentienta Team.
This means Sentienta can draw on a broader developer community building new agents, tools, and workflows—each of which can be brought directly into a team.
As that ecosystem evolves, so does what Sentienta Teams can do.
The Integrated Operational Workspace
To support this shift, we’ve redesigned the Sentienta workspace to keep team configuration, monitoring, and outputs tightly integrated with the live workflow.
- New Team Studio
Manage agents and teams directly from the main workspace. Create agents, edit team compositions, and access the Agent Marketplace without losing session context. - Session Assist
A persistent right-hand workspace for real-time coordination. - Team Artifacts
Automatically summarizes findings and preserves structured outputs. - Pinned Ideas
Keeps core requirements and decisions visible throughout the session. - The Monitor
Provides operational visibility into agent activity and OpenClaw task states, so execution can be tracked alongside reasoning.
End-to-End Example: The Strategic Acquisition Screen
To illustrate this model, we ran a full acquisition analysis workflow end-to-end using a Sentienta Team.
Sentienta agents handled the strategic reasoning. OpenClaw agents operated in parallel to gather external data and produce final outputs.
The result was not just analysis—it was a complete, decision-ready deliverable.
- Parallel Execution
ResearchScout and MarketScout (OpenClaw) gathered external intelligence while the rest of the team progressed in parallel. - Native Synthesis
Maya and Evan (Sentienta) transformed that data into a clear “Pursue” recommendation with supporting rationale. - Direct Output
MaryAnne (OpenClaw) converted that decision into a board-ready PowerPoint, returning the.pptxand slide images directly into the session.
This is the key shift: work doesn’t stop at insight—it continues until it becomes executable artifacts.
Secure, Owner-Controlled Action
Execution happens within your environment.
OpenClaw agents run inside your security perimeter, ensuring that as teams move from reasoning to output, your data remains fully under your control.
From Insight to Outcome
Sentienta remains the place where agent teams solve complex problems.
Now, it is also the place where those solutions are carried through to completion.
Not separate tools.
Not disconnected steps.
One system—from reasoning to result.





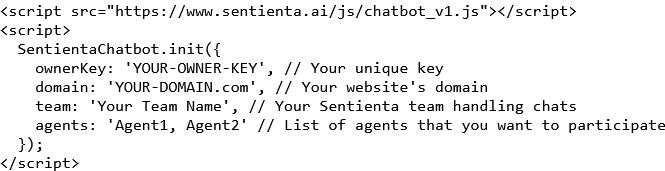
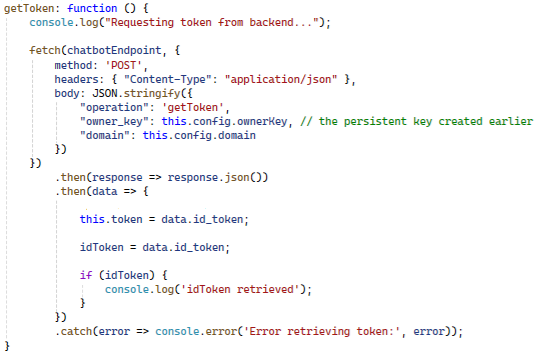
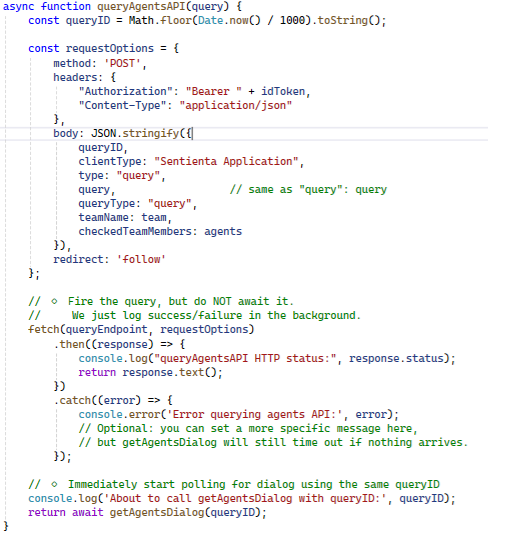


 Introduction
Introduction